
msamancioglu
Mustafa Samancioglu
Recently Published


JHU - Data Science Capstone Course - NGram Assignment (week2)
The goal for this study is to understand the basic features of given text databases (en_US.blogs.tx, ex_US.news.txt and en_US.twitter.txt). To do this, firstly, we are going to identify size (in MBs), line counts and word counts of each text file. Because of the huge sizes of datasets and memory limitations of persenal computer, we will get a smaller sample (10%) from each text file by sample() r function. Secondly, we will get unigrams, bigrams and trigrams from sample dataset and present some summary statistics about ngrams. Finally, we will present some plots and graphs (wordclouds and ngrams frequency distributions) of ngrams for a better understanding of datasets.
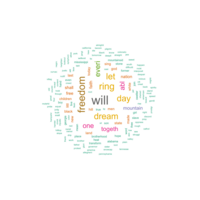
Wordclouds in R Example Project
wordclouds for I have a dream speech
Plot
example plot

Data Products R Presentation Example
Shiny App for BMI calculation

R Markdown Presentation & Plotly
This presentation ise prepared to create a web page presentation using R Markdown that features a plot created with Plotly. And also, to publise prepared webpage presentation on either GitHub Pages, RPubs, or NeoCities.
JHU Data Science Developing Data Products Course Week 2 Leaflet Project
This project was created as part of the Developing Data Products course of the Coursera Data Science Specialization. The goal of the project is to create a web page using R Markdown that features a map created with Leaflet, and to host the resulting web page on either GitHub Pages, RPubs, or NeoCities.
This leaflet map example includes positions of some major cities from Turkey.

Reproducible Research Peer-graded Assignment: Course Project 2
Reproducible Research Peer-graded Assignment: Course Project 2